I often hear in talks from statisticians that P-values are uniformly distributed under the null. But how can this be? And what does it mean? As the demonstration is pretty straightforward but nonetheless hard to find on the Internet, here it is.
Everything starts with an experiment (or at least with the observation of a natural phenomenon, be it part of an experiment or not). The aim is to assess whether or not the hypothesis we have about this phenomenon seems to be true. But first, let’s recall that a parametric test (see Wikipedia) is constituted of:
- data: the
observations
,
, …,
are realizations of
,
, …,
assumed to be identically distributed;
- statistical model: the probability distribution of the
;
- hypothesis: an assertion concerning
for the null (e.g.
), and
for the alternative (e.g.
with
);
- decision rule: given a test statistic
, if it belongs to the critical region
, the null hypothesis
In practice, 
The P-value, noted 


Therefore, according to Wikipedia, a P-value is the probability of obtaining a test statistic at least as extreme as the one that was actually observed, assuming that the null hypothesis is true. According to Matthew Stephens (source), a p value is the proportion of times that you would see evidence stronger than what was observed, against the null hypothesis, if the null hypothesis were true and you hypothetically repeated the experiment (sampling of individuals from a population) a large number of times.
Very importantly, note that the 2nd definition emphasizes the fact that, although it is computed from the data, a P-value does not correspond to the probability that

A P-value simply gives information in the case we would repeat the experiment a large number of times… (That’s why P-values are often decried.)
Ok, back on topic now. From the formula above, we can also write:

By noting 

And here is the trick, thanks to the fact that the cdf is monotonic, increasing and (left-)continuous:
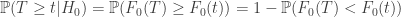
Therefore, we have:
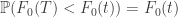
Which means that 

cqfd.
But what does it mean? Well, we usually consider a significance level, noted 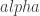

Last but not least, if we re-do the same experiment 100 times and consider a threshold of 5%:
- if
- if now
? at least 23%, and typically 50% (see the paper of Sellke et al in 2001). In other words, when
